
L’arbre de décision est un algorithme de machine learning classique utilisé pour la classification et la régression.
Le principe de base est un arbre de décision qui permet de tracer tous les chemins des décisions possibles sous la forme d’un arbre.
Exemple : Cet arbre montre les survivants du Titanic
« Sibsp » est le nombre de conjoints et frères et sœurs à l’étranger
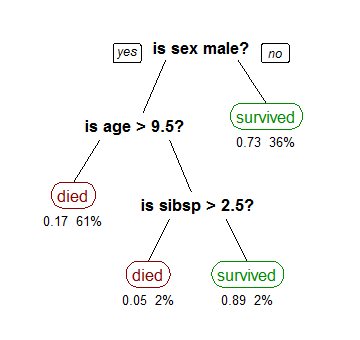
Les pourcentages affichés sous les feuilles représentent les probabilités d’observations.
Chaque chemin allant du noyau jusqu’à la feuille représente un processus de décision.
Essayons maintenant d’analyser l’arbre de décision en utilisant cet exemple:

Comment pouvons nous construire un arbre ?
La construction d’arbres de décision implique le fractionnement.
Dans notre exemple, chaque fonctionnalité ne peut avoir que deux valeurs possibles (« oui » et « non »). Ainsi, chaque fonctionnalité peut être divisée en deux façons.
Nous pouvons répartir toutes les fonctionnalités possibles en deux, mais cela nous donnerait un arbre très important et très inefficace.
Comment pouvons-nous nous assurer d’avoir un arbre raisonnable ?
Avant de diviser à chaque niveau de l’arbre, nous évaluons toutes les fonctionnalités en fonction de leur distribution et décidons quelle fonctionnalité est la meilleure à diviser. Plus formellement, cette fonctionnalité nous donne le gain d’information le plus élevé pour le fractionnement.
Le gain d’information est défini comme la quantité d’informations attendue qui serait nécessaire pour choisir si une nouvelle instance d’entrée devrait être classée «oui» ou «non»